
💡 김영한님의 스프링 핵심 원리 고급편 강의를 듣고 정리한 내용입니다.
프록시 기본 개념
프록시에 대해서 알아보자
클라이언트(Client)와 서버(Server)라고 하면 개발자들은 보통 서버 컴퓨터를 생각한다.사실 클라이언트와 서버의 개념은 상당히 넓게 사용된다. 클라이언트는 의뢰인이라는 뜻이고, 서버는 '서비스나 상품을 제공하는 사람이나 물건'을 뜻한다. 따라서 클라이언트와 서버의 기본 개념을 정의하면 클라이언트는 서버에 필요한 것을 요청하고, 서버는 클라이언트의 요청을 처리하는 것이다.
이 개념을 우리가 익숙한 컴퓨터 네트워크에 도입하면 클라이언트는 웹 브라우저가 되고, 요청을 처리하는 서버는 웹 서버가 된다. 이 개념을 객체에 도입하면, 요청하는 객체는 클라이언트가 되고, 요청을 처리하는 객체는 서버가 된다.
직접 호출과 간접 호출

클라이언트와 서버 개념에서 일반적으로 클라이언트가 서버를 직접 호출하고, 처리 결과를 직접 받는다. 이것을 직접 호출이라 한다.

그런데 클라이언트가 요청한 결과를 서버에 직접 요청하는 것이 아니라 어떤 대리자를 통해서 대신 간접적으로 서버에 요청할 수 있다. 예를 들어서 내가 직접 마트에서 장을 볼 수도 있지만, 누군가에게 대신 장을 봐달라고 부탁할 수도 있다. 여기서 대신 장을 보는 대리자를 영어로 프록시(Proxy)라 한다.
예시
재미있는 점은 직접 호출과 다르게 간접 호출을 하면 대리자가 중간에서 여러가지 일을 할 수 있다는 점이다.
- 엄마에게 라면을 사달라고 부탁 했는데, 엄마는 그 라면은 이미 집에 있다고 할 수도 있다. 그러면 기대한 것 보다 더 빨리 라면을 먹을 수 있다. (접근 제어, 캐싱)
- 아버지께 자동차 주유를 부탁했는데, 아버지가 주유 뿐만 아니라 세차까지 하고 왔다. 클라이언트가 기대한 것 외에 세차라는 부가 기능까지 얻게 되었다. (부가 기능 추가)
- 그리고 대리자가 또 다른 대리자를 부를 수도 있다. 예를 들어서 내가 동생에게 라면을 사달라고 했는데, 동생은 또 다른 누군가에게 라면을 사달라고 다시 요청할 수도 있다. 중요한 점은 클라이언트는 대리자를 통해서 요청했 기 때문에 그 이후 과정은 모른다는 점이다. 동생을 통해서 라면이 나에게 도착하기만 하면 된다. (프록시 체인)

대체 가능
그런데 여기까지 듣고 보면 아무 객체나 프록시가 될 수 있는 것 같다.
객체에서 프록시가 되려면, 클라이언트는 서버에게 요청을 한 것인지, 프록시에게 요청을 한 것인지 조차 몰라야 한다. 쉽게 이야기해서 서버와 프록시는 같은 인터페이스를 사용해야 한다. 그리고 클라이언트가 사용하는 서버 객체를 프록시 객체로 변경해도 클라이언트 코드를 변경하지 않고 동작할 수 있어야 한다.
서버와 프록시가 같은 인터페이스 사용
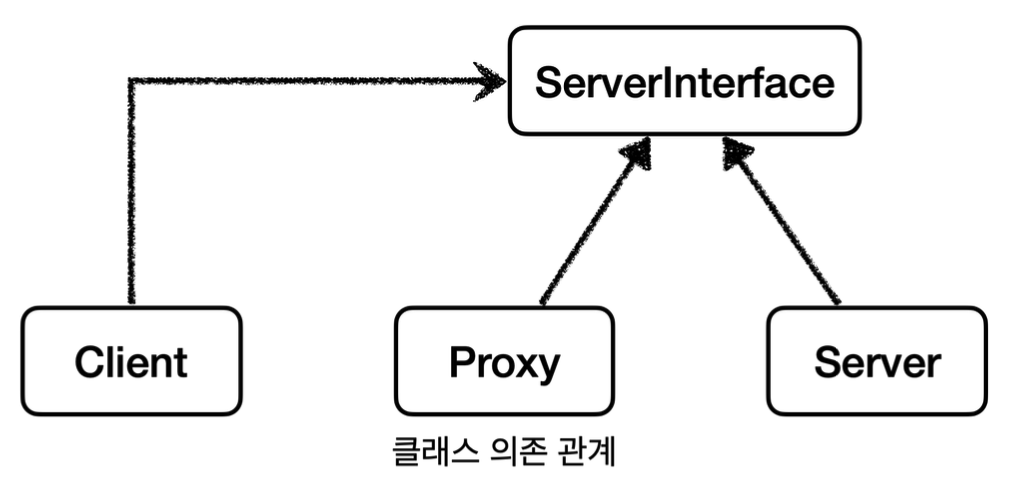
클래스 의존관계를 보면 클라이언트는 서버 인터페이스( ServerInterface )에만 의존한다.
그리고 서버와 프록시가 같은 인터페이스를 사용한다. 따라서 DI를 사용해서 대체 가능하다.
런타임 객체 의존 관계


이번에는 런타임 객체 의존 관계를 살펴보자. 런타임(애플리케이션 실행 시점)에 클라이언트 객체에 DI를 사용해서 Client -> Server에서 Client -> Proxy로 객체 의존관계를 변경해도 클라이언트 코드를 전혀 변경하지 않아도 된다. 클라이언트 입장에서는 변경 사실 조차 모른다. DI를 사용하면 클라이언트 코드의 변경 없이 유연하게 프록시를 주입할 수 있다.
프록시의 주요 기능
프록시를 통해서 할 수 있는 일은 크게 2가지로 구분할 수 있다.
접근 제어
- 권한에 따른 접근 차단
- 캐싱
- 지연 로딩
부가 기능 추가
- 원래 서버가 제공하는 기능에 더해서 부가 기능을 수행한다.
- 예) 요청 값이나, 응답 값을 중간에 변형한다.
- 예) 실행 시간을 측정해서 추가 로그를 남긴다.
프록시 객체가 중간에 있으면 크게 접근 제어와 부가 기능 추가를 수행할 수 있다.
GOF 디자인 패턴
둘다 프록시를 사용하는 방법이지만 GOF 디자인 패턴에서는 이 둘을 의도(intent)에 따라서 프록시 패턴과 데코레이터 패턴으로 구분한다.
- 프록시 패턴: 접근 제어가 목적(캐시, 보안 등)
- 데코레이터 패턴: 새로운 기능 추가가 목적
둘다 프록시를 사용하지만, 의도가 다르다는 점이 핵심이다.
용어가 프록시 패턴이라고 해서 이 패턴만 프록시를 사용하는 것은 아니다. 데코레이터 패턴도 프록시를 사용한다. 프록시 패턴과 프록시는 아에 다른 개념이다. 프록시 패턴은 디자인 패턴의 이름을 이렇게 지은거다.
이왕 프록시를 학습하기로 했으니 GOF 디자인 패턴에서 설명하는 프록시 패턴과 데코레이터 패턴을 나누어 학습해보자.
참고: 프록시라는 개념은 클라이언트 서버라는 큰 개념안에서 자연스럽게 발생할 수 있다.
프록시는 객체안에서 의 개념도 있고, 웹 서버에서의 프록시도 있다.
객체안에서 객체로 구현되어있는가, 웹 서버로 구현되어 있는가 처럼 규모의 차이가 있을 뿐 근본적인 역할은 같다.
프록시 패턴 예제 코드


Subject
public interface Subject {
String operation();
}RealSubject
@Slf4j
public class RealSubject implements Subject {
@Override
public String operation() {
log.info("실제 객체 호출");
sleep(1000);
return "data";
}
private void sleep(int millis) {
try {
Thread.sleep(millis);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}RealSubject는 Subject 인터페이스를 구현했다.
operation()은 데이터 조회를 시뮬레이션 하기 위해 1초 쉬도록 했다.
예를 들어서 데이터를 DB나 외부에서 조회하는데 1초가 걸린다고 생각하면 된다.
호출할 때 마다 시스템 에 큰 부하를 주는 데이터 조회라고 가정
ProxyPatternClient
public class ProxyPatternClient {
private Subject subject;
public ProxyPatternClient(Subject subject) {
this.subject = subject;
}
public void execute() {
subject.operation();
}
}Subject 인터페이스에 의존하고, Subject를 호출하는 클라이언트 코드이다.
ProxyPatternTest
public class ProxyPatternTest {
@Test
void noProxyTest() {
RealSubject realSubject = new RealSubject();
ProxyPatternClient client = new ProxyPatternClient(realSubject);
client.execute();
client.execute();
client.execute();
}
}데이터가 한번 조회하면 변하지 않는 데이터라면 어딘가에 보관해두고 이미 조회한 데이터를 사용하는 것이 성능상 좋다. 이런 것을 캐시라고 한다. 프록시 패턴의 주요 기능은 접근 제어이다. 캐시도 접근 자체를 제어하는 기능 중 하나이다.
이미 개발된 로직을 전혀 수정하지 않고, 프록시 객체를 통해서 캐시를 적용해보자.
프록시 패턴 - 프록시 객체를 통해 캐시 적용


CacheProxy
@Slf4j
public class CacheProxy implements Subject {
private Subject target;
private String cacheValue;
public CacheProxy(Subject target) {
this.target = target;
}
@Override
public String operation() {
log.info("프록시 호출");
if (cacheValue == null) {
cacheValue = target.operation();
}
return cacheValue;
}
}앞서 설명한 것 처럼 프록시도 실제 객체와 그 모양이 같아야 하기 때문에 Subject 인터페이스를 구현해야 한다.
- private Subject target: 클라이언트가 프록시를 호출하면 프록시가 최종적으로 실제 객체를 호출해야 한다. 따라서 내부에 실제 객체의 참조를 가지고 있어야 한다. 이렇게 프록시가 호출하는 대상을 target 이라 한다. 현재 상황에서는 target에 RealSubject 객체가 담긴다고 보면 된다.
- operation()` : 구현한 코드를 보면 cacheValue에 값이 없으면 실제 객체( target)를 호출해서 값을 구한다. 그리고 구한 값을 cacheValue에 저장하고 반환한다. 만약 cacheValue에 값이 있으면 실제 객체를 전혀 호출하지 않고, 캐시 값을 그대로 반환한다. 따라서 처음 조회 이후에는 캐시( cacheValue )에서 매우 빠르게 데이터를 조회할 수 있다.
cacheProxyTest
public class ProxyPatternTest {
@Test
void cacheProxyTest() {
RealSubject realSubject = new RealSubject();
CacheProxy cacheProxy = new CacheProxy(realSubject);
ProxyPatternClient client = new ProxyPatternClient(cacheProxy);
client.execute();
client.execute();
client.execute();
}
}realSubject와 cacheProxy를 생성하고 둘을 연결한다.
결과적으로 cacheProxy가 realSubject를 참조하는 런타임 객체 의존관계가 완성된다.
그리고 마지막으로 client에 realSubject가 아닌 cacheProxy를 주입한다.
이 과정을 통해서 client -> cacheProxy -> realSubject 런타임 객체 의존 관계가 완성된다.
cacheProxyTest()는 client.execute()을 총 3번 호출한다.
이번에는 클라이언트가 실제 realSubject를 호출하는 것이 아니라 cacheProxy를 호출하게 된다.
캐시 프록시 도입 이후에는 최초에 한번만 1초가 걸리고, 이후에는 거의 즉시 반환한다.
정리
프록시 패턴의 핵심은 RealSubject 코드와 클라이언트 코드를 전혀 변경하지 않고, 프록시를 도입해서 접근 제어를 했다는 점이다. 그리고 클라이언트 코드의 변경 없이 자유롭게 프록시를 넣고 뺄 수 있다. 실제 클라이언트 입장에서는 프록시 객체가 주입되었는지, 실제 객체가 주입되었는지 알지 못한다.
인터페이스 기반 프록시 적용
인터페이스와 구현체가 있는 V1 App에 지금까지 학습한 프록시를 도입해서 LogTrace를 사용해보자.
프록시를 사용하면 기존 코드를 전혀 수정하지 않고 로그 추적 기능을 도입할 수 있다.
V1 App의 기본 클래스 의존 관계와 런타임시 객체 인스턴스 의존 관계는 다음과 같다.
V1 기본 클래스 의존 관계
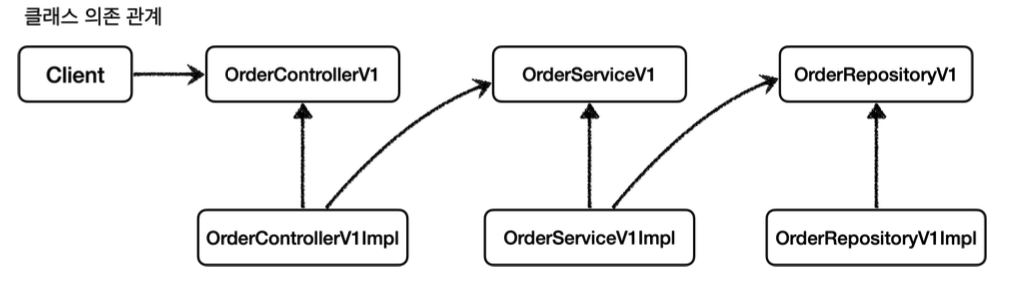
V1 런타임 객체 의존 관계

여기에 로그 추적용 프록시를 추가하면 다음과 같다.
V1 프록시 의존 관계 추가
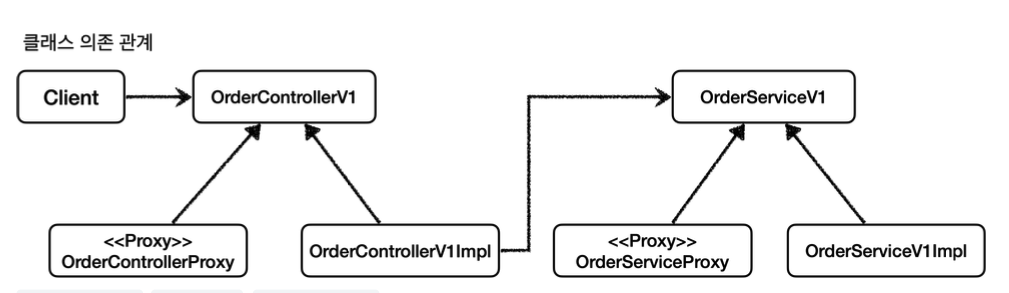
`Controller` , `Service` , `Repository` 각각 인터페이스에 맞는 프록시 구현체를 추가한다.
V1 프록시 런타임 객체 의존 관계
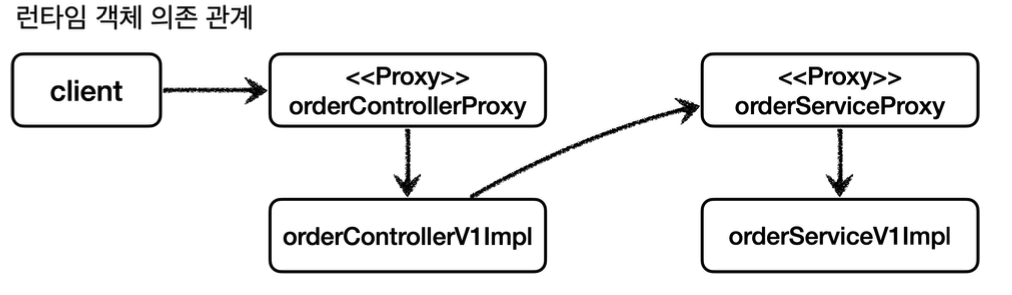
그리고 애플리케이션 실행 시점에 프록시를 사용하도록 의존 관계를 설정해주어야 한다.
이 부분은 빈을 등록하는 설정 파일을 활용하면 된다.
그럼 실제 프록시를 코드에 적용해보자.
OrderRepositoryInterfaceProxy
@RequiredArgsConstructor
public class OrderControllerInterfaceProxy implements MyOrderControllerV1 {
private final MyOrderControllerV1 target;
private final LogTrace logTrace;
@Override
public String request(String itemId) {
TraceStatus status = null;
try {
status = logTrace.begin("OrderController.request()");
//target 호출
String result = target.request(itemId);
logTrace.end(status);
return result;
} catch (Exception e) {
logTrace.exception(status, e);
throw e;
}
}
@Override
public String noLog() {
return target.noLog();
}
}OrderRepositoryV1 target: 프록시가 실제 호출할 원본 리포지토리의 참조를 가지고 있어야 한다.
OrderServiceInterfaceProxy
@RequiredArgsConstructor
public class OrderServiceInterfaceProxy implements MyOrderServiceV1 {
private final MyOrderServiceV1 target;
private final LogTrace logTrace;
@Override
public void orderItem(String itemId) {
TraceStatus status = null;
try {
status = logTrace.begin("OrderService.orderItem()");
//target 호출
target.orderItem(itemId);
logTrace.end(status);
} catch (Exception e) {
logTrace.exception(status, e);
throw e;
}
}
}InterfaceProxyConfig
@Configuration
public class InterfaceProxyConfig {
@Bean
public MyOrderControllerV1 orderController(LogTrace logTrace) {
MyOrderControllerV1Impl controllerImpl = new MyOrderControllerV1Impl(orderService(logTrace));
return new OrderControllerInterfaceProxy(controllerImpl, logTrace);
}
@Bean
public MyOrderServiceV1 orderService(LogTrace logTrace) {
MyOrderServiceV1Impl serviceImpl = new MyOrderServiceV1Impl(orderRepository(logTrace));
return new OrderServiceInterfaceProxy(serviceImpl, logTrace);
}
@Bean
public MyOrderRepositoryV1 orderRepository(LogTrace logTrace) {
MyOrderRepositoryV1Impl repositoryImpl = new MyOrderRepositoryV1Impl();
return new OrderRepositoryInterfaceProxy(repositoryImpl, logTrace);
}
}V1 프록시 런타임 객체 의존 관계 설정
이제 프록시의 런타임 객체 의존 관계를 설정하면 된다.
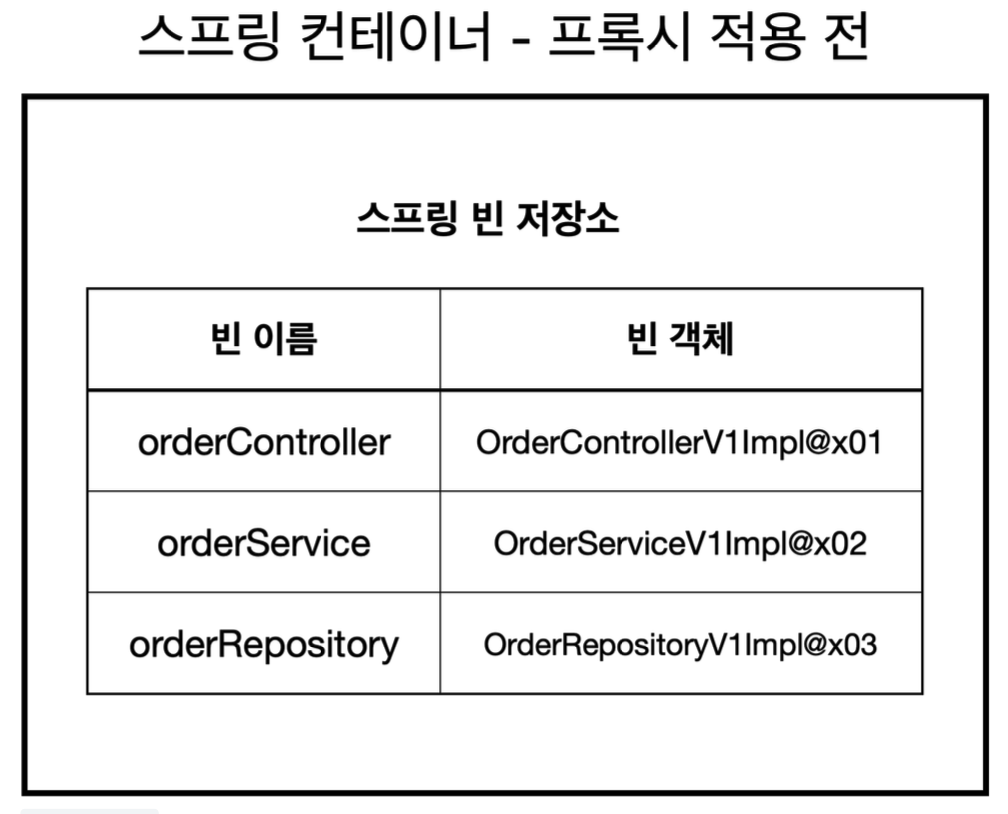
기존에는 스프링 빈이 orderControlerV1Impl, orderServiceV1Impl같은 실제 객체를 반환했다.
하지만 이제는 프록시를 사용해야한다. 따라서 프록시를 생성하고 프록시를 실제 스프링 빈 대신 등록한다.
실제 객체는 스프링 빈으로 등록하지 않는다. 프록시는 내부에 실제 객체를 참조하고 있다.
예를 들어서 OrderServiceInterfaceProxy는 내부에 실제 대상 객체인 OrderServiceV1Impl을 가지고 있다.
정리하면 다음과 같은 의존 관계를 가지고 있다.
- proxy -> target
- orderServiceInterfaceProxy -> orderServiceV1Impl
스프링 빈으로 실제 객체 대신에 프록시 객체를 등록했기 때문에 앞으로 스프링 빈을 주입 받으면 실제 객체 대신에 프록시 객체가 주입된다.
실제 객체가 스프링 빈으로 등록되지 않는다고 해서 사라지는 것은 아니다. 프록시 객체가 실제 객체를 참조하기 때문에 프록시를 통해서 실제 객체를 호출할 수 있다. 쉽게 이야기해서 프록시 객체 안에 실제 객체가 있는 것이다.
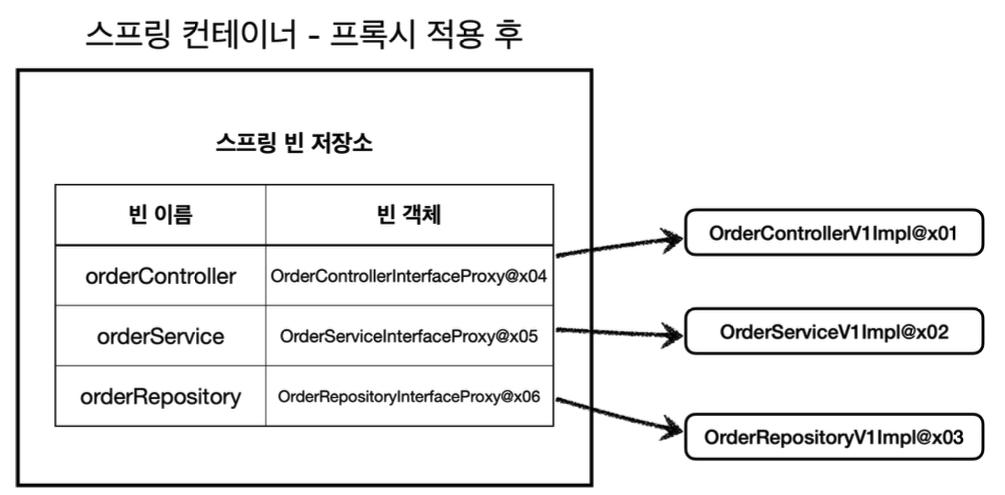
InterfaceProxyConfig를 통해 프록시를 적용한 후
스프링 컨테이너에 프록시 객체가 등록된다.
스프링 컨테이너는 이제 실제 객체가 아니라 프록시 객체를 스프링 빈으로 관리한다.
이제 실제 객체는 스프링 컨테이너와는 상관이 없다. 실제 객체는 프록시 객체를 통해서 참조될 뿐이다.
프록시 객체는 스프링 컨테이너가 관리하고 자바 힙 메모리에도 올라간다.
반면에 실제 객체는 자바 힙 메모리에 는 올라가지만 스프링 컨테이너가 관리하지는 않는다.
구체 클래스 기반 프록시 적용 예시
이번에는 구체 클래스에 프록시를 적용하는 방법을 학습해보자.
클래스 기반 프록시 도입
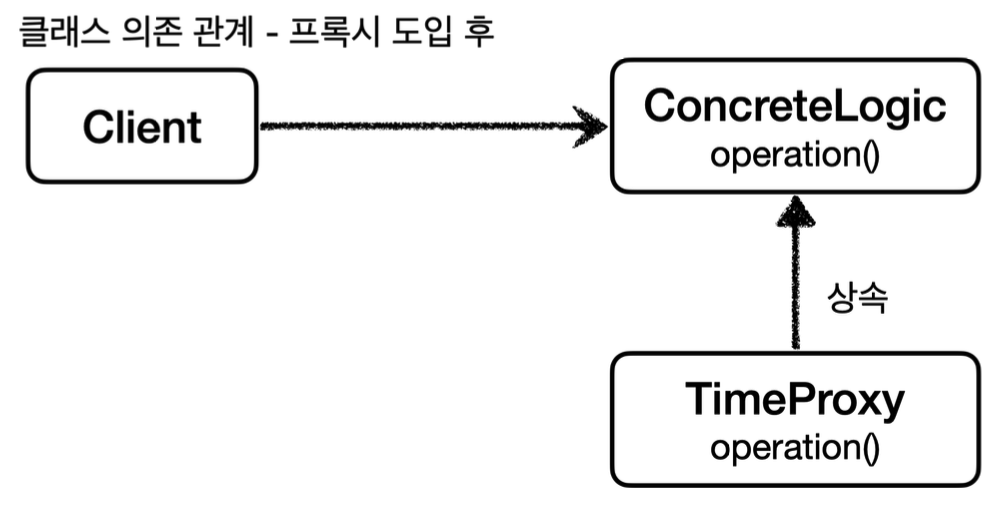
지금까지 인터페이스를 기반으로 프록시를 도입했다. 그런데 자바의 다형성은 인터페이스를 구현하든, 아니면 클래스를 상속하든 상위 타입만 맞으면 다형성이 적용된다. 쉽게 이야기해서 인터페이스가 없어도 프록시를 만들수 있다는 뜻이다. 그래서 이번에는 인터페이스가 아니라 클래스를 기반으로 상속을 받아서 프록시를 만들어보겠다.

ConcreteClient
public class ConcreteClient {
private ConcreteLogic concreteLogic;
public ConcreteClient(ConcreteLogic concreteLogic) {
this.concreteLogic = concreteLogic;
}
public void execute() {
concreteLogic.operation();
}
}ConcreteLogic
@Slf4j
public class ConcreteLogic {
public String operation() {
log.info("ConcreteLogic 실행");
return "data";
}
}TimeProxy
@Slf4j
public class TimeProxy extends ConcreteLogic {
private ConcreteLogic concreteLogic;
public TimeProxy(ConcreteLogic concreteLogic) {
this.concreteLogic = concreteLogic;
}
@Override
public String operation() {
log.info("TimeDecorator 실행");
long startTime = System.currentTimeMillis();
String result = concreteLogic.operation();
long endTime = System.currentTimeMillis();
long resultTime = endTime - startTime;
log.info("TimeDecorator 종료 resultTime={}ms", resultTime);
return result;
}
}TimeProxy 프록시는 시간을 측정하는 부가 기능을 제공한다.
그리고 인터페이스가 아니라 클래스인 ConcreteLogic를 상속 받아서 만든다.
ConcreteProxyTest - addProxy() 추가
public class ConcreteProxyTest {
...
@Test
void addProxy() {
ConcreteLogic concreteLogic = new ConcreteLogic();
TimeProxy timeProxy = new TimeProxy(concreteLogic);
ConcreteClient client = new ConcreteClient(timeProxy);
client.execute();
}
}여기서 핵심은 ConcreteClient의 생성자에 concreteLogic이 아니라 timeProxy를 주입하는 부분이다.
ConcreteClient는 `ConcreteLogic을 의존하는데, 다형성에 의해 ConcreteLogic에 concreteLogic도 들어갈 수 있고, timeProxy도 들어갈 수 있다.
구체 클래스 기반 프록시 적용
OrderServiceConcreteProxy
public class OrderServiceConcreteProxy extends MyOrderServiceV2 {
private final MyOrderServiceV2 target;
private final LogTrace logTrace;
public OrderServiceConcreteProxy(MyOrderServiceV2 target, LogTrace logTrace) {
super(null);
this.target = target;
this.logTrace = logTrace;
}
@Override
public void orderItem(String itemId) {
TraceStatus status = null;
try {
status = logTrace.begin("OrderService.orderItem()");
//target 호출
target.orderItem(itemId);
logTrace.end(status);
} catch (Exception e) {
logTrace.exception(status, e);
throw e;
}
}
}인터페이스가 아닌 OrderServiceV2 클래스를 상속 받아서 프록시를 만든다.
클래스 기반 프록시의 단점
super(null): OrderServiceV2: 자바 기본 문법에 의해 자식 클래스를 생성할 때는 항상 super()로 부모 클래스의 생성자를 호출해야 한다. 이 부분을 생략하면 기본 생성자가 호출된다. 그런데 부모 클래스인 OrderServiceV2는 기본 생성자가 없고, 생성자에서 파라미터 1개를 필수로 받는다. 따라서 파라미터를 넣어서 super(..)를 호출해야 한다. 프록시는 부모 객체의 기능을 사용하지 않기 때문에 super(null)을 입력해도 된다. 인터페이스 기반 프록시는 이런 고민을 하지 않아도 된다.
ConcreteProxyConfig
@Configuration
public class ConcreteProxyConfig {
@Bean
public MyOrderControllerV2 orderControllerV2(LogTrace logTrace) {
MyOrderControllerV2 controllerImpl = new MyOrderControllerV2(orderServiceV2(logTrace));
return new OrderControllerConcreteProxy(controllerImpl, logTrace);
}
@Bean
public MyOrderServiceV2 orderServiceV2(LogTrace logTrace) {
MyOrderServiceV2 serviceImpl = new MyOrderServiceV2(orderRepositoryV2(logTrace));
return new OrderServiceConcreteProxy(serviceImpl, logTrace);
}
@Bean
public MyOrderRepositoryV2 orderRepositoryV2(LogTrace logTrace) {
MyOrderRepositoryV2 repositoryImpl = new MyOrderRepositoryV2();
return new OrderRepositoryConcreteProxy(repositoryImpl, logTrace);
}
}인터페이스 대신에 구체 클래스를 기반으로 프록시를 만든다는 것을 제외하고는 기존과 같다.
인터페이스 기반 프록시와 클래스 기반 프록시
프록시
프록시를 사용한 덕분에 원본 코드를 전혀 변경하지 않고, V1, V2 애플리케이션에 LogTrace 기능을 적용할 수 있었 다.
인터페이스 기반 프록시 vs 클래스 기반 프록시
- 인터페이스가 없어도 클래스 기반으로 프록시를 생성할 수 있다.
- 클래스 기반 프록시는 해당 클래스에만 적용할 수 있다.
- 인터페이스 기반 프록시는 인터페이스만 같으면 모든 곳에 적용할 수 있다.
- 클래스 기반 프록시는 상속을 사용하기 때문에 몇가지 제약이 있다.
- 부모 클래스의 생성자를 호출해야 한다.(앞서 본 예제)
- 클래스에 final 키워드가 붙으면 상속이 불가능하다.
- 메서드에 final 키워드가 붙으면 해당 메서드를 오버라이딩 할 수 없다.
이렇게 보면 인터페이스 기반의 프록시가 더 좋아보인다. 맞다.
인터페이스 기반의 프록시는 상속이라는 제약에서 자유롭다.
프로그래밍 관점에서도 인터페이스를 사용하는 것이 역할과 구현을 명확하게 나누기 때문에 더 좋다.
인터페이스 기반 프록시의 단점은 인터페이스가 필요하다는 그 자체이다.
인터페이스가 없으면 인터페이스 기반 프록시를 만들 수 없다.
참고
인터페이스 기반 프록시는 캐스팅 관련해서 단점이 있는데, 이 내용은 강의 뒷부문에서 설명한다.
이론적으로는 모든 객체에 인터페이스를 도입해서 역할과 구현을 나누는 것이 좋다.
이렇게 하면 역할과 구현을 나누어서 구현체를 매우 편리하게 변경할 수 있다.
하지만 실제로는 구현을 거의 변경할 일이 없는 클래스도 많다. 인터페이스를 도입하는 것은 구현을 변경할 가능성이 있을 때 효과적인데, 구현을 변경할 가능성이 거의 없는 코드에 무 작정 인터페이스를 사용하는 것은 번거롭고 그렇게 실용적이지 않다. 이런곳에는 실용적인 관점에서 인터페이스를 사용 하지 않고 구체 클래스를 바로 사용하는 것이 좋다 생각한다. (물론 인터페이스를 도입하는 다양한 이유가 있다. 여기서 핵심은 인터페이스가 항상 필요하지는 않다는 것이다.)
결론
실무에서는 프록시를 적용할 때 V1처럼 인터페이스도 있고, V2처럼 구체 클래스도 있다.
따라서 2가지 상황을 모두 대 응할 수 있어야 한다.
너무 많은 프록시 클래스
지금까지 프록시를 사용해서 기존 코드를 변경하지 않고, 로그 추적기라는 부가 기능을 적용할 수 있었다.
그런데 문제는 프록시 클래스를 너무 많이 만들어야 한다는 점이다. 잘 보면 프록시 클래스가 하는 일은 LogTrace를 사용하는 것인데, 그 로직이 모두 똑같다. 대상 클래스만 다를 뿐이다. 만약 적용해야 하는 대상 클래스가 100개라면 프록시 클래스도 100개를 만들어야한다.
프록시 클래스를 하나만 만들어서 모든 곳에 적용하는 방법은 없을까?
바로 다음에 설명할 동적 프록시 기술이 이 문제를 해결해준다.