
개요
안녕하세요, 이번에 Filmeet 프로젝트에서 구현한 컬렉션 기능에 대해 이야기하는 글을 작성하려고 합니다.
프로젝트를 진행하며 해당 기능을 설계하고 구현하는 과정에서 느낀 점과 경험을 공유하고자 합니다.
컬렉션 기능 소개

컬렉션 기능은 사용자가 자신이 좋아하는 영화를 담는 기능입니다.
컬렉션에는 영화를 추가할 수 있을 뿐만 아니라, 작성자가 직접 제목과 내용을 작성할 수도 있습니다.
또한, 컬렉션에는 댓글을 남기거나 좋아요를 누르는 기능도 제공됩니다.
이번 글에서는 컬렉션에 영화를 담는 과정에 대해 소개하려고 합니다.
컬렉션 기능 요구 사항 분석
컬렉션 기능을 구현하기에 앞서, 요구 사항 분석을 진행했습니다.
요구 사항
- 사용자는 컬렉션(제목, 내용)을 작성, 수정, 삭제할 수 있다.
- 사용자는 여러 개의 영화를 컬렉션에 저장, 수정, 삭제할 수 있다.
- 사용자는 컬렉션에 좋아요를 누르거나 댓글을 작성할 수 있다.
아래 상황처럼 사용자는 기존 저장된 영화를 제거할 수 있고 새로 영화를 추가할 수 있습니다.
따라서 프론트에서 서버로 보낼 수정할 값은 우선 제목, 내용, 영화 ID 값들로 파악했습니다.


제목과 내용은 JPA의 dirty checking을 통해 쉽게 수정할 수 있습니다.
문제는 컬렉션에 저장된 기존 영화에 대한 수정과 삭제입니다
처음 생각한 로직은 기존에 저장된 영화를 싹 제거하고 새로 받은 영화 ID 값들로 새로 저장하는 방식입니다.
기존에 저장된 영화는 내버려두고 새로 영화를 추가할 수도 있고 또는 새로 영화를 추가하지 않고 기존 영화만 삭제하는 경우도 존재합니다. 하지만 위 방식으로 하면 반드시 delete 쿼리와 insert 쿼리가 발생해 불필요한 쿼리가 발생한다고 생각했다.
그래서 삭제할 부분만 삭제하고 새로 추가할 부분만 추가하는 방식으로 로직을 수정했습니다.
우선은 기존에 저장된 영화 ID값들을 조회하고 프론트가 보낸 영화 ID값들과 비교해서 삭제할 영화들 추가할 영화들을 결정하고 만약에 삭제할 영화 ID 값들이 있을 경우 delete 쿼리를 보내 삭제하고 추가할 영화 ID 값들이 있으면 Insert 쿼리를 보내 추가하는 식으로 로직을 설계했습니다.
컬렉션의 제목과 내용은 JPA의 Dirty Checking을 통해 쉽게 수정할 수 있습니다.
하지만, 컬렉션에 저장된 기존 영화의 수정 및 삭제는 조금 더 복잡한 문제였습니다.
초기 설계
처음에는 기존에 저장된 영화를 모두 삭제하고, 새로운 영화 ID 리스트로 다시 저장하는 방식을 고려했습니다.
이 방식은 간단하지만, 다음과 같은 문제가 있었습니다
- 기존 영화는 그대로 두고 새로운 영화를 추가하는 경우
- 새로운 영화를 추가하지 않고 기존 영화만 삭제하는 경우
이 방식에서는 항상 DELETE와 INSERT 쿼리가 발생하여 불필요한 쿼리가 수행된다고 판단했습니다.
개선된 로직
이를 해결하기 위해, 삭제할 영화만 삭제하고, 추가할 영화만 추가하는 방식으로 로직을 수정했습니다.
- 기존에 저장된 영화의 ID 목록을 조회합니다.
- 프론트에서 전달된 새로운 영화 ID 목록과 비교하여,
- 삭제할 영화 ID와 추가할 영화 ID를 결정합니다.
- 삭제할 영화가 있다면 DELETE 쿼리를, 추가할 영화가 있다면 INSERT 쿼리를 수행하는 방식으로 설계했습니다.
이러한 방식으로 불필요한 데이터베이스 연산을 최소화했습니다.
최종적으로 설계한 로직을 바탕으로 아래와 같이 코드를 만들었습니다.
컬렉션 수정 서비스 로직
public Long modifyCollection(CollectionModifyRequest modifyRequest, Long userId) {
User user = userRepository.findById(userId)
.orElseThrow(CollectionUserNotFoundException::new);
// 1. 컬렉션 조회
Collection collection = collectionRepository.findById(modifyRequest.collectionId())
.orElseThrow(CollectionNotFoundException::new);
// 2. 컬렉션 제목과 내용 수정
collection.modifyCollection(badWordService.maskText(modifyRequest.title()),
badWordService.maskText(modifyRequest.content()));
// 3. 기존에 저장된 영화 ID 목록 가져오기
List<Long> existingMovieIds = collectionMovieRepository.findMovieIdsByCollectionId(collection.getId());
// 4. 새로 요청된 영화 ID 목록
List<Long> newMovieIds = modifyRequest.movieIds();
// 5. 삭제할 영화와 추가할 영화 계산
List<Long> moviesToRemove = existingMovieIds.stream()
.filter(movieId -> !newMovieIds.contains(movieId))
.toList();
List<Long> moviesToAdd = newMovieIds.stream()
.filter(movieId -> !existingMovieIds.contains(movieId))
.collect(Collectors.toList());
// 6. 삭제할 영화 처리
if (!moviesToRemove.isEmpty()) {
collectionMovieRepository.deleteByCollectionIdAndMovieIds(collection.getId(), moviesToRemove);
// 삭제된 영화의 장르 점수 업데이트 (점수 감소)
List<Movie> moviesToRemoveEntities = movieRepository.findMoviesWithGenreByMovieIds(moviesToRemove);
updateGenreScoresForUser(user, moviesToRemoveEntities, -user.getCollectionActivityScore());
}
// 7. 추가할 영화 처리
if (!moviesToAdd.isEmpty()) {
List<Movie> movies = movieRepository.findMoviesWithGenreByMovieIds(moviesToAdd);
collectionMovieBulkRepository.saveAll(collection, movies);
// 추가된 영화의 장르 점수 업데이트 (점수 증가)
updateGenreScoresForUser(user, movies, user.getCollectionActivityScore());
}
return collection.getId();
}
삭제는 @Modifying을 사용해 벌크 연산으로 처리하여, 쿼리 발생 횟수를 최소화했습니다.
삭제 처리
@Modifying
@Query("DELETE FROM CollectionMovie cm " +
"WHERE cm.collection.id = :collectionId AND cm.movie.id IN :movieIds")
void deleteByCollectionIdAndMovieIds(@Param("collectionId") Long collectionId,
@Param("movieIds") List<Long> movieIds);
삽입 역시 벌크 연산으로 처리하기 위해 JdbcTemplate을 사용해 배치 방식으로 여러 영화를 한 번에 저장하도록 구현했습니다.
삽입 처리
@Repository
@RequiredArgsConstructor
public class CollectionMovieBulkRepository {
private final JdbcTemplate jdbcTemplate;
@Transactional
public void saveAll(Collection collection, List<Movie> movies) {
String sql = "INSERT INTO collection_movie (collection_id, movie_id) VALUES (?, ?)";
List<Object[]> batchArgs = movies.stream()
.map(movie -> new Object[]{collection.getId(), movie.getId()})
.toList();
jdbcTemplate.batchUpdate(sql, batchArgs);
}
}컬렉션 목록 조회 요구 사항 분석
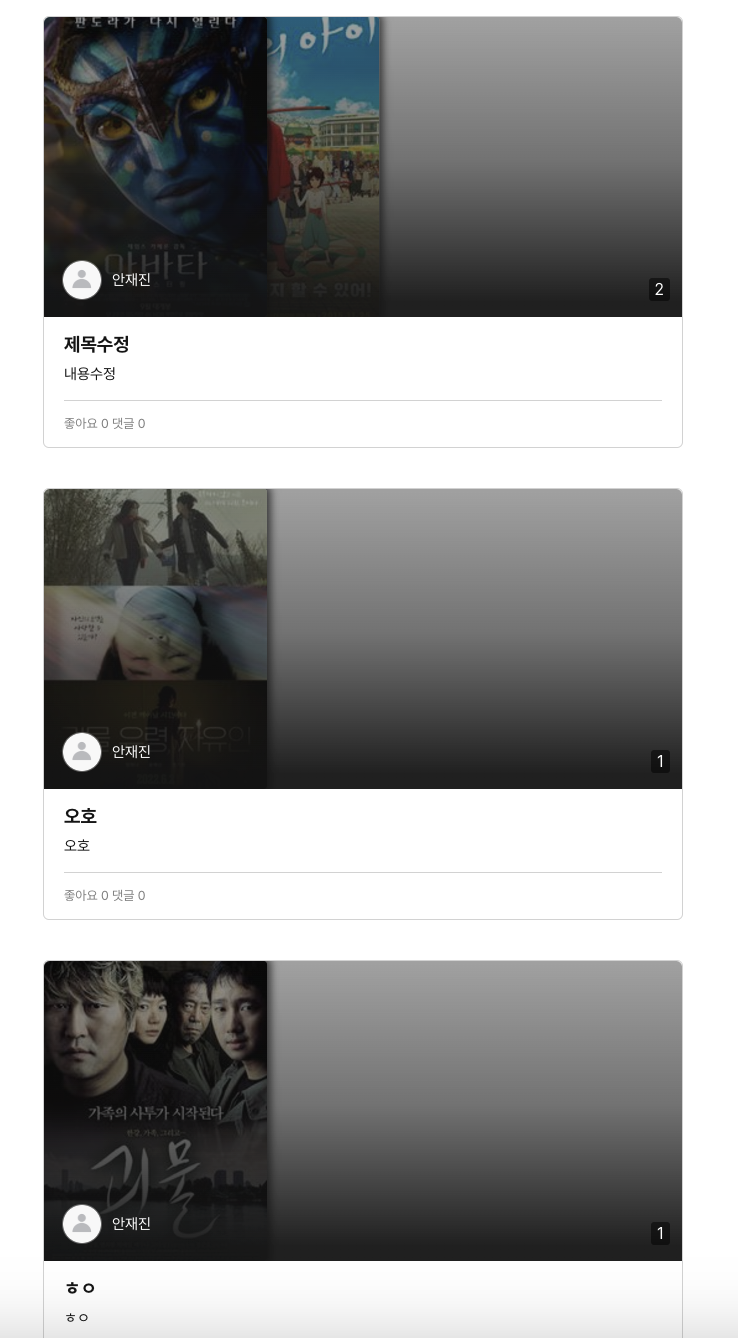
보이는 것처럼 프론트엔드에 전달할 데이터는 다음과 같이 구성됩니다.
- 유저 정보 – 이름 및 프로필 이미지
- 컬렉션 정보 – 제목 및 내용
- 컬렉션에 저장된 영화 정보 – 포스터 이미지(+ 기타 영화 데이터)
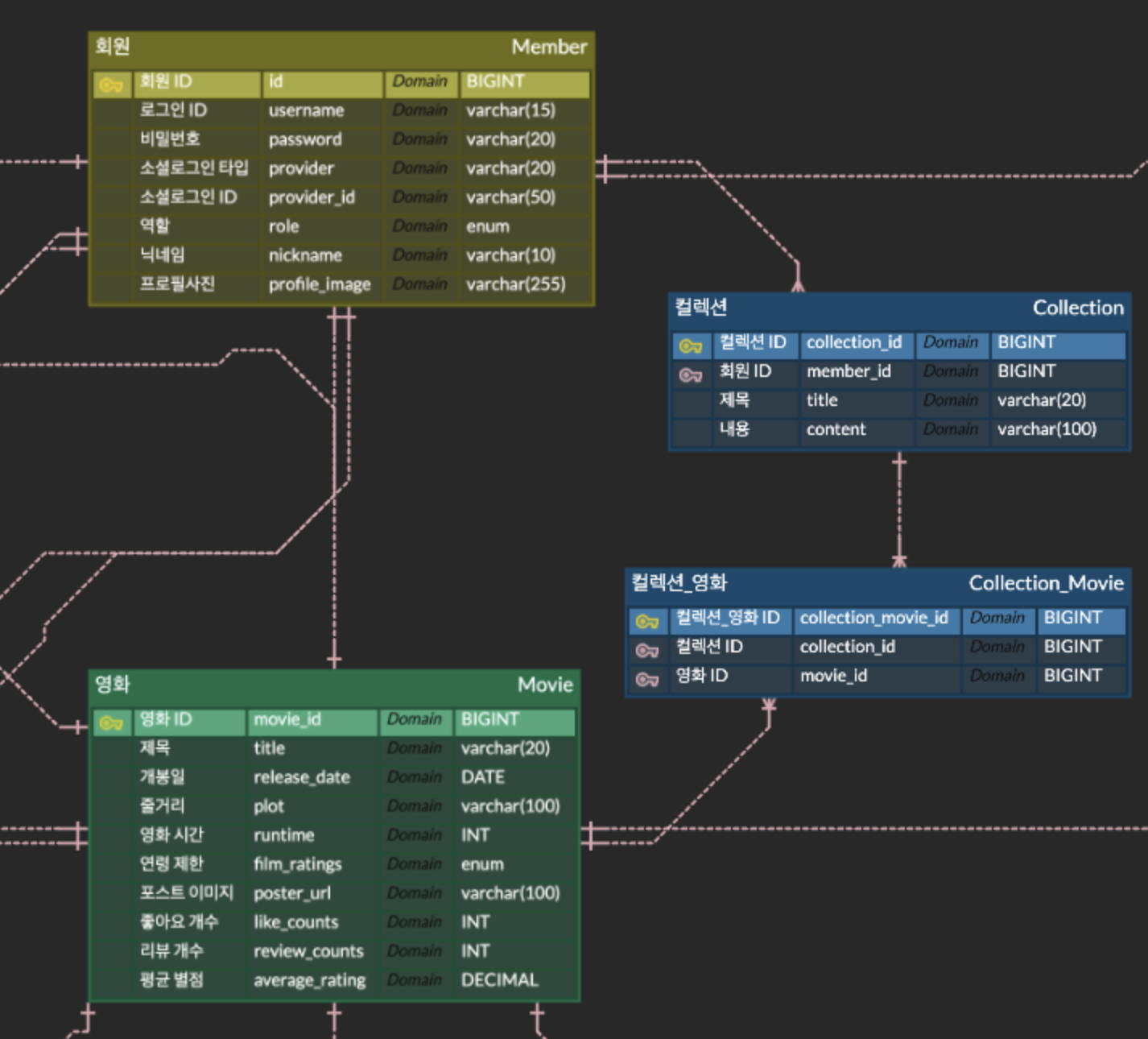
위 ERD는 Filmeet 프로젝트의 일부입니다.
요구사항을 분석한 결과, 회원 테이블, 컬렉션 테이블, 영화 테이블에서 데이터를 조회하는 방식으로 설계했습니다.
1. 유저 정보 조회
컬렉션은 해당 유저의 데이터여야 하므로,
프론트엔드로부터 유저의 ID 값을 전달받아 이를 기반으로 유저 정보를 조회하는 방식으로 시작했습니다.
2. 초기 로직 설계
처음 구상한 방식은 유저 정보를 기반으로 컬렉션 - 컬렉션_영화 - 영화 테이블을 조인하여 데이터를 가져오는 방식이었습니다.
하지만, 컬렉션_영화와 컬렉션 테이블 간의 관계는 다대일 단방향으로 설정되어 있었습니다.
문제점:
- 컬렉션에서 컬렉션_영화로 접근할 수는 있지만, 컬렉션_영화에서 컬렉션으로 접근하는 것은 불가능했습니다.
- 이를 해결하기 위해 양방향 관계를 고려했지만, 이는 수정 로직이 복잡해질 것이라 판단했습니다.
3. 개선된 로직 설계
- 회원 ID를 기준으로 해당 유저의 컬렉션 목록을 페이징 처리하여 조회하는 방식을 채택했습니다.
- 이후, 조회한 컬렉션에서 컬렉션 ID만 추출하고,
- 해당 ID를 바탕으로 컬렉션_영화와 영화 테이블을 페치 조인하여 필요한 데이터를 한 번에 조회하도록 설계했습니다.
4. 데이터 매핑
조회한 영화 데이터를 각 컬렉션에 매핑하기 위해, 스트림(Stream) 기능을 사용하여 컬렉션과 영화 데이터를 가독성 있게 매핑하였습니다.
최종적으로 아래와 같이 코드를 작성했습니다.
public Slice<CollectionsResponse> getCollections(Long userId, int page, int size) {
User user = userRepository.findById(userId)
.orElseThrow(CollectionUserNotFoundException::new);
Pageable pageable = PageRequest.of(page, size, Sort.Direction.DESC, "createdAt");
Slice<Collection> collections = collectionRepository.findCollectionsByUserId(user.getId(), pageable);
List<Long> collectionIds = collections.getContent()
.stream()
.map(Collection::getId)
.toList();
List<CollectionMovie> collectionMovies = collectionMovieRepository.findMoviesByCollectionIds(collectionIds);
return collections.map(collection ->
CollectionsResponse.from(
collection,
getCollectionMovies(collection.getId(), collectionMovies)
)
);
}
private List<CollectionMovieInfoResponse> getCollectionMovies(Long collectionId,
List<CollectionMovie> collectionMovies) {
return collectionMovies.stream()
.filter(cm -> cm.getCollection().getId().equals(collectionId))
.map(cm -> new CollectionMovieInfoResponse(
cm.getMovie().getId(),
cm.getMovie().getTitle(),
cm.getMovie().getPosterUrl(),
cm.getMovie().getReleaseDate(),
cm.getMovie().getRuntime(),
cm.getMovie().getFilmRatings(),
cm.getMovie().getAverageRating(),
cm.getMovie().getLikeCounts(),
cm.getMovie().getRatingCounts()
))
.toList();
}위 코드에서 스트림 중심으로 좀 더 상세히 설명해 보겠습니다.
영화 목록 필터링 및 DTO 매핑 스트림
return collectionMovies.stream()
.filter(cm -> cm.getCollection().getId().equals(collectionId)) // 특정 컬렉션 ID만 필터링
.map(cm -> new CollectionMovieInfoResponse( // DTO로 매핑
cm.getMovie().getId(),
cm.getMovie().getTitle(),
cm.getMovie().getPosterUrl(),
cm.getMovie().getReleaseDate(),
cm.getMovie().getRuntime(),
cm.getMovie().getFilmRatings(),
cm.getMovie().getAverageRating(),
cm.getMovie().getLikeCounts(),
cm.getMovie().getRatingCounts()
))
.toList();- collectionMovies.stream() : CollectionMovie 리스트에 대해 스트림을 생성합니다.
- .filter(cm -> cm.getCollection().getId().equals(collectionId))
- filter는 중간 연산으로, collectionId와 일치하는 CollectionMovie만 필터링합니다.
- .map(cm -> new CollectionMovieInfoResponse(...))
- 각 CollectionMovie 객체를 DTO(CollectionMovieInfoResponse)로 변환합니다.
- 영화의 제목, 포스터, 평점 등 필요한 정보를 추출해 새로운 객체로 매핑합니다.
- .toList() – 최종 연산으로 결과를 List로 반환합니다.
목적
- 특정 컬렉션에 속한 영화만 필터링하고, 이를 DTO로 변환해 필요한 데이터 형태로 가공합니다.
- filter와 map을 조합해 필터링 및 변환을 동시에 수행합니다.
반환된 결과를 매핑하는 스트림
return collections.map(collection ->
CollectionsResponse.from(
collection,
getCollectionMovies(collection.getId(), collectionMovies)
)
);
- collections.map : Slice<Collection>의 map 메서드를 호출해 각 컬렉션을 순회하며 DTO로 변환합니다.
- getCollectionMovies : 해당 컬렉션에 맞는 영화 목록을 필터링하고 매핑합니다.
- CollectionsResponse.from – 컬렉션 정보와 영화 목록을 조합해 최종 응답 DTO를 생성합니다.
목적
- 각 컬렉션별로 영화 목록을 매핑해 CollectionsResponse DTO로 변환합니다.
그래서 최종적으로 아래와 같이 출력되게 만들었습니다.
{
"code": 200,
"message": "Success",
"data": {
"content": [
{
"collectionId": 16,
"collectionTitle": "제목",
"collectionContent": "내용",
"userName": "이름",
"userProfileImage": "이미지",
"movies": [
{
"movieId": 1,
"title": "제목",
"posterImage": "asdf",
"releaseDate": "2024-11-18",
"runtime": 150,
"filmRatings": "FIFTEEN",
"averageRating": 1.3,
"likeCount": 11,
"reviewCount": 20
},
...
{
"movieId": 13,
"title": "제목13",
"posterImage": "asdf",
"releaseDate": "2024-10-01",
"runtime": 150,
"filmRatings": "ADULT",
"averageRating": 2.1,
"likeCount": 1,
"reviewCount": 5
}
]
},
...
{
"collectionId": 14,
"collectionTitle": "제목",
"collectionContent": "내용",
"userName": "이름",
"userProfileImage": "이미지",
"movies": []
},
...
]
}
],
...
},
"timestamp": "2024-11-20T22:30:06.221763"
}마무리 하며
Filmeet 프로젝트에서 구현한 컬렉션 기능에 대해 소개하는 글을 작성했습니다.
이 글에서는 로직 설계부터 구현 과정까지 상세히 기록하여,
나중에 잊어버리더라도 다시 참고할 수 있도록 정리했습니다.
또한, 이 글이 비슷한 기능을 구현하는 분들께 도움이 되기를 바라며 작성했습니다. 😊
'프로젝트 > Filmeet' 카테고리의 다른 글
| 콘텐츠 기반 추천과 유사 사용자 기반 추천을 결합한 하이브리드 추천 시스템 만들기 (3) | 2024.12.19 |
|---|---|
| Redis 분산 락을 활용하여 동시성 문제 해결하기 (0) | 2024.12.04 |
| @Query with "not in" not work with empty List parameter (0) | 2024.12.02 |
| MultipleBagFetchException - 두 개 이상의 OneToMany 관계에서 N+1 문제 최적화하기 (0) | 2024.11.22 |
| 동적 조건 처리를 위한 Querydsl 사용하기 (0) | 2024.11.21 |