
개요
이번 글에서는 Filmeet 프로젝트에 적용한 redis 분산 락에 대해 글을 작성하려 합니다.
아래는 Movie 엔티티입니다.
현재 Filmeet 프로젝트에서는 영화 조회 API가 다양하게 사용되고 있으며, 영화 정보를 조회할 때 좋아요 수, 평균 평점 등의 데이터가 함께 필요한 경우가 많습니다.
하지만, 영화 데이터를 조회할 때마다 매번 해당 영화의 전체 좋아요 수와 평균 평점을 계산하는 쿼리가 발생한다면, DB 부하가 커질 수 있다고 판단했습니다.
이를 해결하기 위해, Movie 엔티티에 좋아요 수, 평점 수, 평균 평점 필드를 추가하는 방식으로 반정규화를 진행했습니다. 이를 통해 조회 성능을 향상하고, 불필요한 쿼리 호출을 최소화하여 시스템의 효율성을 높이고자 했습니다.
@Getter
@Entity
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Movie extends BaseEntity {
@Id
@Column(name = "movie_id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
...
private Integer likeCounts = 0;
private Integer ratingCounts = 0;
private BigDecimal averageRating = BigDecimal.ZERO;
...
}동시성 문제 발생
아래는 초기 서비스 로직으로, 락(Lock)이 적용되지 않은 상태에서의 비즈니스 로직입니다.
이 로직을 기반으로, 1000명의 유저가 동시에 같은 영화에 좋아요를 한 번씩 누르는 시나리오로 테스트 코드를 작성했습니다. 정상적으로 동작한다면, 해당 영화의 좋아요 수는 1000개여야 합니다.
@Service
@Transactional
@RequiredArgsConstructor
public class MovieLikeCommandServiceV1 implements MovieLikeCommandService {
private final UserRepository userRepository;
private final MovieRepository movieRepository;
private final MovieLikesRepository movieLikesRepository;
private final GenreScoreRepository genreScoreRepository;
@Override
public void movieLikes(Long movieId, Long userId) {
boolean isAlreadyLiked = movieLikesRepository.existsByMovieIdAndUserId(movieId, userId);
if (isAlreadyLiked) {
throw new MovieLikeAlreadyExistsException();
}
Movie movie = movieRepository.findMovieWithGenreByMovieId(movieId)
.orElseThrow(MovieNotFoundException::new);
User user = userRepository.findById(userId)
.orElseThrow(MovieUserNotFoundException::new);
MovieLikes movieLikes = MovieLikes.builder()
.movie(movie)
.user(user)
.build();
movieLikesRepository.save(movieLikes);
updateGenreScoresForUser(userId, movie, GenreScoreAction.LIKE);
movie.addLikeCounts();
}
...
}@DisplayName("좋아요_개수_분산락_적용_락_흐름조정_AOP_사용_동시성_1000명_테스트")
@Test
void likeCountWithDistributedLockAdjustedFlowUsingAOPConcurrency1000Test() throws InterruptedException {
// given
Movie movie = createMovie("제목", "줄거리", LocalDate.now(), 150, "https://poster.jpg", FilmRatings.ADULT);
Genre genre = createGenre(GenreType.ACTION);
MovieGenre movieGenre = createMovieGenre(movie, genre);
movieRepository.save(movie);
genreRepository.save(genre);
movieGenreRepository.save(movieGenre);
List<User> users = new ArrayList<>();
for (int i = 1; i <= 1000; i++) {
User user = createUser("user" + i, "password", Role.ROLE_ADULT_USER, Provider.NAVER, "닉네임" + i,
"https://example.com/profile" + i + ".jpg");
users.add(user);
}
userRepository.saveAll(users);
// when
int numberOfThreads = 1000;
ExecutorService executorService = Executors.newFixedThreadPool(numberOfThreads);
CountDownLatch latch = new CountDownLatch(numberOfThreads);
for (int i = 0; i < numberOfThreads; i++) {
long userId = users.get(i).getId();
executorService.submit(() -> {
try {
movieLikeCommandServiceV1.movieLikes(movie.getId(), userId);
} finally {
latch.countDown();
}
});
}
latch.await();
executorService.shutdown();
// then
Optional<Movie> findMovie = movieRepository.findById(movie.getId());
assertThat(findMovie).isPresent();
assertThat(findMovie.get().getLikeCounts()).isEqualTo(1000);
}

2024-12-23T22:08:58.752+09:00 WARN 37968 --- [ol-5-thread-838] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Error: 1213, SQLState: 40001
2024-12-23T22:08:58.752+09:00 WARN 37968 --- [ol-5-thread-836] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Error: 1213, SQLState: 40001
2024-12-23T22:08:58.752+09:00 ERROR 37968 --- [ol-5-thread-836] o.h.engine.jdbc.spi.SqlExceptionHelper : Deadlock found when trying to get lock; try restarting transaction
2024-12-23T22:08:58.752+09:00 ERROR 37968 --- [ol-5-thread-838] o.h.engine.jdbc.spi.SqlExceptionHelper : Deadlock found when trying to get lock; try restarting transaction
2024-12-23T22:08:58.752+09:00 WARN 37968 --- [ool-5-thread-31] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Error: 1213, SQLState: 40001
2024-12-23T22:08:58.752+09:00 ERROR 37968 --- [ool-5-thread-31] o.h.engine.jdbc.spi.SqlExceptionHelper : Deadlock found when trying to get lock; try restarting transaction
2024-12-23T22:08:58.752+09:00 WARN 37968 --- [ol-5-thread-837] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Error: 1213, SQLState: 40001
2024-12-23T22:08:58.752+09:00 ERROR 37968 --- [ol-5-thread-837] o.h.engine.jdbc.spi.SqlExceptionHelper : Deadlock found when trying to get lock; try restarting transaction
2024-12-23T22:08:58.752+09:00 WARN 37968 --- [ol-5-thread-839] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Error: 1213, SQLState: 40001
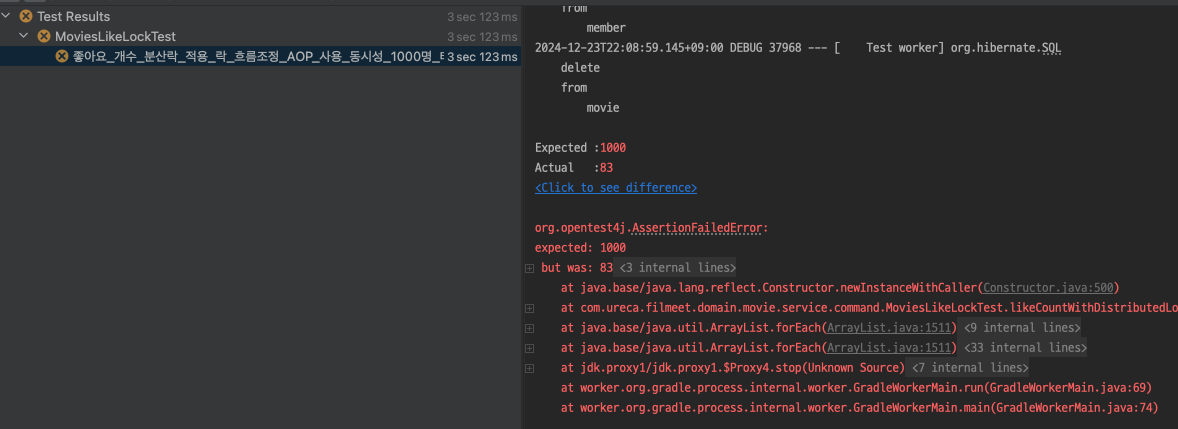
2024-12-23T22:08:58.752+09:00 ERROR 37968 --- [ol-5-thread-839] o.h.engine.jdbc.spi.SqlExceptionHelper : Deadlock found when trying to get lock; try restarting transaction테스트 결과, 좋아요 개수가 정상적으로 1000개가 저장되지 않고 83개만 저장되었습니다.
이는 여러 스레드가 동시에 영화의 좋아요 개수에 접근해 값을 변경하는 과정에서 동시성 문제가 발생했기 때문입니다. 이 테스트를 통해, 멀티스레드 환경에서의 동시 접근으로 인해 데이터 불일치가 발생할 수 있음을 확인했습니다.
해당 문제를 해결하기 위해, 영화 엔티티의 좋아요 개수 업데이트 구간에 락(Lock)을 적용하여 동시성 문제를 방지하는 방향으로 개선을 진행했습니다.
락 정하기
락을 사용한다면 크게 3가지 방식으로 사용할 수 있습니다.
- 애플리케이션 레벨에서의 락
- DB 락
- 분산 락
각 락 옵션에 대한 장단점을 알아보겠습니다.
1. 애플리케이션 레벨에서의 락 (예: ReentrantLock 또는 synchronized)
- 장점: 구현이 간단하고 성능 저하가 적음. JVM 내에서 관리되므로 설정이 쉬움.
- 단점: 단일 인스턴스의 애플리케이션에서만 유효. 만약 여러 서버 인스턴스가 있으면, 락이 다른 인스턴스에는 적용되지 않으므로 동일한 로직이 중복 실행될 수 있음.
2. DB 락 (예: MySQL의 SELECT FOR UPDATE, row-level locking)
- 장점: 데이터베이스에서 락을 관리하므로, 다중 서버 환경에서도 락이 유지됨. 일반적인 트랜잭션과 함께 사용할 수 있어 일관성 유지가 쉬움.
- 단점: 데이터베이스에 추가적인 락 부하를 발생시켜 성능 저하가 발생할 수 있음. 락 경쟁이 많아지면, DB의 성능에 직접적인 영향을 미칠 수 있음.
3. 분산 락 (예: Redis의 SETNX)
- 장점: 여러 서버 인스턴스에서 락을 공유할 수 있어, 분산 환경에서 중복 작업을 방지할 수 있음. Redis와 같은 분산 락을 사용하면, 특정 시점에 하나의 인스턴스만 작업을 수행하게 보장할 수 있음.
- 단점: Redis와 같은 별도의 시스템이 필요하므로 설정과 관리가 복잡해질 수 있음.
그렇다면 현재 Filmeet 프로젝트에서는 어떤 락을 사용하면 좋을까요?
분산 락 사용
ReentrantLock와 synchronized 같이 애플리케이션 레벨에서 락을 사용하면 분산 환경에서는 문제가 해결되지 않습니다. 그래서 DB 락과 분산 락에 대해 고민했고 DB 락 같은 경우에는 커넥션 풀 고갈이나 데드락 문제로 인해 분산 락을 사용하기로 결정했습니다.
그렇다면 어떤 분산 락을 사용하는 게 좋을까요?
ZooKeeper vs Redis 분산 락
어떤 분산 락들이 있는지 찾아봤고 각 분산 락 중 어떤 락을 사용할지 고민했습니다.
ZooKeeper
다음으로는 ZooKeeper 락에 대해 찾아봤습니다.
ZooKeeper 락의 경우, 고가용성과 일관성을 보장하는 것이 큰 장점입니다. 락이 노드 단위로 관리되기 때문에 장애 발생 시 자동 복구가 가능합니다. 다만, 단점으로는 ZooKeeper 자체의 운영 및 유지보수 비용이 발생하며, Redis에 비해 락 획득 속도가 느리고, 설정이 복잡할 수 있다는 점이 있습니다.
Redis 분산 락
마지막으로 Redis 분산 락에 대해 찾아봤습니다.
Redis 분산 락의 장점으로는 인메모리 기반이므로 락 획득/해제 속도가 빠르며 Redlock 알고리즘을 사용하면 Redis 클러스터 환경에서 강력한 분산 락을 구현 가능하다고 합니다. 단점으로는 네트워크 장애가 발생하면 락이 풀릴 가능성이 있고 노드 장애나 애플리케이션 중지로 인해 잠금 상태가 예상과 다르게 유지될 가능성도 있다고 합니다.
최종적으로 Redis를 활용한 분산 락을 선택했습니다.
조사 과정에서 MySQL 네임드 락은 성능 이슈가 크다는 점을 확인했습니다.
ZooKeeper는 Redis 분산 락보다 더 안정적인 락 솔루션을 제공하지만, 이는 고객 자산과 같은 민감한 데이터에서 정합성을 엄격하게 보장해야 하는 경우에 적합하다고 판단했습니다.
반면, 저희 팀은 '좋아요 개수'와 같이 정합성이 엄격하게 요구되지 않는 기능에 대해 Redis 분산 락을 적용했습니다.
Redis는 빠른 응답 속도와 간단한 설정이라는 장점이 있으며, 저희의 요구 사항을 충분히 충족한다고 판단했습니다.
또한, ZooKeeper는 러닝 커브가 높고, 참고할 자료가 상대적으로 부족하다는 점도 고려해야 했습니다.
결과적으로, MySQL 네임드 락보다 성능이 우수하고, 자료가 풍부해 구현 및 유지보수가 용이한 Redis 분산 락을 선택하게 되었습니다.
Redis 분산 락 - Lettuce vs Redisson
Lettuce
Lettuce는 Redis의 SETNX 명령어를 활용한 스핀락(Spin Lock) 방식으로 분산 락을 구현합니다.
SETNX란?
SETNX는 "SET if Not eXist"의 약자로, 특정 키가 존재하지 않을 경우에만 값을 설정하는 Redis 명령어입니다.
이를 활용하면, 특정 키에 대해 락을 획득하는 효과를 낼 수 있습니다.
작동 방식
- 락 획득 과정
- SETNX를 사용하여 해당 키가 존재하는지 확인합니다.
- 키가 존재하지 않으면 값을 세팅하고 락을 획득합니다.
- 키가 이미 존재하는 경우, 락이 걸려 있다고 간주하고, 락이 해제될 때까지 재시도(Spin)합니다.
- 원자적 연산
- SETNX는 원자적(Atomic)으로 동작하여, 값이 존재하는지 확인하고 값을 세팅하는 과정이 한 번의 연산으로 수행됩니다.
- 이로 인해, 경합 상황에서도 데이터 정합성을 보장할 수 있습니다.
- 스핀락 방식
- 락이 획득되지 않으면, 일정 시간 대기 후 반복적으로 SETNX를 호출하여 락을 재시도합니다.
- 이러한 방식은 간단하지만 Redis에 부하를 줄 수 있는 단점이 존재합니다.
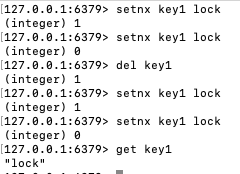
Lettuce로 구현한 스핀락 예제입니다.
(출처 : https://hyperconnect.github.io/2019/11/15/redis-distributed-lock-1.html )
private RedisTemplate rt;
/**Lettuce 라이브러리 대신 spring data redis를 사용하면
키를 획득할 때 timeout을 적용할 수 있습니다.**/
public void SampleSpinLock(final String key,
...//비지니스 로직 파라미터)
throws InterruptedException {
Boolean getKey;
do {
getKey = rt
.opsForValue() //redis의 String(key, val) 사용
.setIfAbsent(String.valueOf(key), //key
"lock", //value
300L, //wait time
TimeUnit.MILLISECONDS); //setnx 사용 명령어
}
while (!getKey) {
Thread.sleep(50);//과도한 반복으로 인한 부하를 막기 위해 약간의 sleep을 사용
}
if (!getKey) return;//타임아웃 후에도 key를 얻지 못했으면 종료
try {
//비지니스 로직
} finally {
//키 반납
rt.delete(String.valueOf(key));
}
}재시도 횟수를 정하는 로직을 더할 수는 있지만 기본적으로 스핀락은 일정 시간 이후 레디스에게 setnx 요청을 하게 됩니다. 요청이 많을수록 레디스에 더 많은 부하가 발생하게 됩니다.
Lettuce는 스핀락을 사용해서 반복적으로 락 획득을 시도하기 때문에 레디스에 많은 부하가 발생합니다.
이럼 점 때문에 Redisson의 RLock 을 사용했습니다.
Redisson - RLock 사용하기
지금까지의 설명은 분산 락의 필요성과 배경에 대한 이야기였습니다.
이제, 본격적으로 프로젝트에서 분산 락을 어떻게 적용했는지 설명드리겠습니다.
build.gradle
implementation 'org.redisson:redisson-spring-boot-starter:3.18.0'Redisson 라이브러리를 사용하기 위해 의존성을 추가합니다.
RedisConfig.java
@Configuration
@RequiredArgsConstructor
public class RedisConfig {
@Value("${spring.data.redis.host}")
private String redisHost;
@Value("${spring.data.redis.port}")
private int redisPort;
private static final String REDISSON_HOST_PREFIX = "redis://";
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
config.useSingleServer().setAddress(REDISSON_HOST_PREFIX + redisHost + ":" + redisPort);
return Redisson.create(config);
}
}RedissonClient를 사용하기 위해 Config 설정을 빈으로 등록합니다.
서비스 로직
@Transactional
@Override
public void movieLikes(Long movieId, Long userId) {
RLock lock = redissonClient.getLock("v2:movieLikes:" + movieId);
try {
// 분산 락 획득
if (lock.tryLock(10, 3, TimeUnit.SECONDS)) { // waitTime: 10초, leaseTime: 3초
// 좋아요 존재 여부 확인
boolean isAlreadyLiked = movieLikesRepository.existsByMovieIdAndUserId(movieId, userId);
if (isAlreadyLiked) {
throw new MovieLikeAlreadyExistsException();
}
// 영화 데이터 가져오기
Movie movie = movieRepository.findMovieWithGenreByMovieId(movieId)
.orElseThrow(MovieNotFoundException::new);
// 사용자 데이터 가져오기
User user = userRepository.findById(userId)
.orElseThrow(MovieUserNotFoundException::new);
// 좋아요 데이터 생성 및 저장
MovieLikes movieLikes = MovieLikes.builder()
.movie(movie)
.user(user)
.build();
movieLikesRepository.save(movieLikes);
// 장르 점수 업데이트
updateGenreScoresForUser(userId, movie, GenreScoreAction.LIKE);
// 영화 좋아요 수 증가
movie.addLikeCounts();
} else {
throw new RuntimeException("Unable to acquire lock for movieLikes");
}
} catch (InterruptedException e) {
throw new RuntimeException("Failed to acquire lock due to interruption", e);
} finally {
// 락 해제
if (lock.isLocked() && lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}위와 같이 서비스 로직에 분산 락을 사용하는 코드를 넣어봤습니다.
그리고 실제로 테스트가 잘 통과하는지 돌려봤습니다.
테스트 코드
@DisplayName("좋아요_개수_분산락_적용_락_흐름조정_AOP_사용_동시성_1000명_테스트")
@Test
void likeCountWithDistributedLockAdjustedFlowUsingAOPConcurrency1000Test() throws InterruptedException {
// given
Movie movie = createMovie("제목", "줄거리", LocalDate.now(), 150, "https://poster.jpg", FilmRatings.ADULT);
Genre genre = createGenre(GenreType.ACTION);
MovieGenre movieGenre = createMovieGenre(movie, genre);
movieRepository.save(movie);
genreRepository.save(genre);
movieGenreRepository.save(movieGenre);
List<User> users = new ArrayList<>();
for (int i = 1; i <= 1000; i++) {
User user = createUser("user" + i, "password", Role.ROLE_ADULT_USER, Provider.NAVER, "닉네임" + i,
"https://example.com/profile" + i + ".jpg");
users.add(user);
}
userRepository.saveAll(users);
// when
int numberOfThreads = 1000;
ExecutorService executorService = Executors.newFixedThreadPool(numberOfThreads);
CountDownLatch latch = new CountDownLatch(numberOfThreads);
for (int i = 0; i < numberOfThreads; i++) {
long userId = users.get(i).getId();
executorService.submit(() -> {
try {
movieLikeCommandServiceV4.movieLikes(movie.getId(), userId);
} finally {
latch.countDown();
}
});
}
latch.await();
executorService.shutdown();
// then
Optional<Movie> findMovie = movieRepository.findById(movie.getId());
assertThat(findMovie).isPresent();
assertThat(findMovie.get().getLikeCounts()).isEqualTo(1000);
}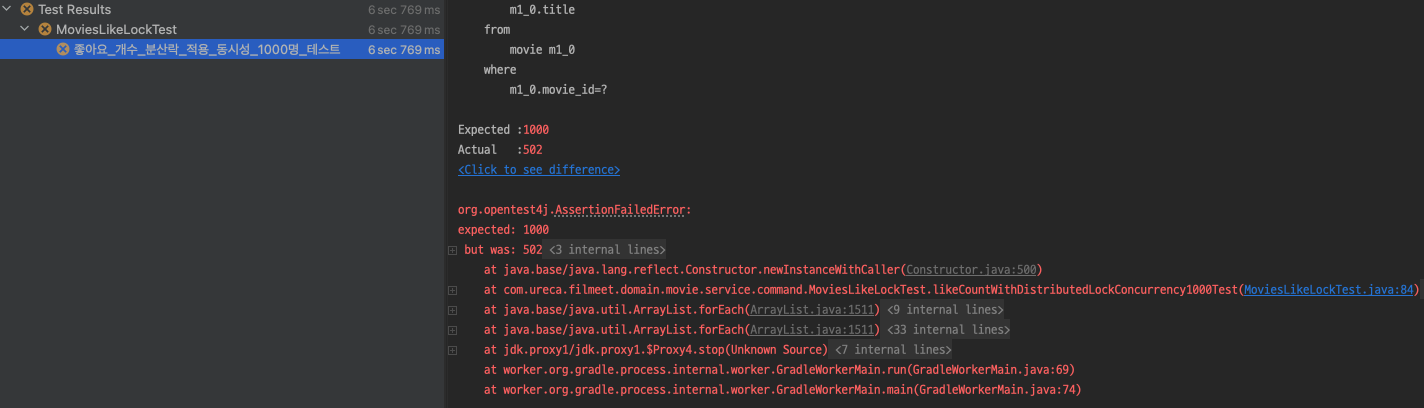

결과는 충격적 이게도 실패했습니다.
분명 분산 락을 적용했는데 테스트에 실패했습니다.
테스트 실패 이유
무엇 때문에 예상과 다르게 Distributed Lock이 동작된 것일까요
문제는 Spring Transaction Commit과 Distributed Lock 반납 시점차가 존재하는 것입니다.

위에 그림과 같이 Distributed Lock 반납이 Spring Transaction Commit보다 먼저 실행되어 해당 시점에 다른 요청이 있는 경우 Commit 이전의 데이터를 조회하여 예상과 다른 결과가 나타나게 됩니다.
다시 말해 트랜잭션 시작 -> 락 획득 -> 로직 실행 -> 락 반납 -> 트랜잭션 종료 이 단계에서 첫 번째 요청에 대한 부분에서 락을 반납하고 트랜잭션이 종료되어 커밋하기 전에 두 번째 요청에 의한 트랜잭션이 시작되고 락을 획득할 수가 있습니다. 이렇게 되면 첫 번째 요청이 로직을 실행해 영화의 좋아요 개수를 업데이트하기 전에, 두 번째 요청이 현재 좋아요 개수를 조회하게 됩니다. 결과적으로, 동시성 문제가 발생해 첫 번째 요청의 업데이트가 반영되지 않은 상태에서 두 번째 요청이 처리됩니다.
문제 해결
이러한 문제를 해결하기 위해, 트랜잭션 흐름을 다음과 같이 수정했습니다.
락 획득 → 트랜잭션 시작 → 로직 실행 → 트랜잭션 종료 → 락 반납
이 방식은 락을 먼저 획득한 후 트랜잭션을 시작하기 때문에, 트랜잭션이 완료될 때까지 다른 요청이 락을 획득하지 못하도록 보장합니다.
서비스 로직
@Override
public void movieLikes(Long movieId, Long userId) {
RLock lock = redissonClient.getLock("v3:movieLikes:" + movieId);
try {
if (lock.tryLock(10000, 3000, TimeUnit.MILLISECONDS)) {
movieLikeHelperService.movieLikes(userId, movieId);
} else {
throw new RuntimeException("Unable to acquire lock for movieLikes: " + movieId);
}
} catch (InterruptedException e) {
throw new RuntimeException("Error while acquiring lock", e);
} finally {
if (lock.isLocked() && lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}@Service
@RequiredArgsConstructor
public class MovieLikeHelperService {
...
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void movieLikes(Long userId, Long movieId) {
boolean isAlreadyLiked = movieLikesRepository.existsByMovieIdAndUserId(movieId, userId);
if (isAlreadyLiked) {
throw new MovieLikeAlreadyExistsException();
}
Movie movie = movieRepository.findMovieWithGenreByMovieId(movieId)
.orElseThrow(MovieNotFoundException::new);
User user = userRepository.findById(userId)
.orElseThrow(MovieUserNotFoundException::new);
MovieLikes movieLikes = MovieLikes.builder()
.movie(movie)
.user(user)
.build();
movieLikesRepository.save(movieLikes);
updateGenreScoresForUser(userId, movie, GenreScoreAction.LIKE);
movie.addLikeCounts();
}
...
}테스트 코드는 수정 없이 그대로 사용했습니다.

실행결과 테스트가 잘 통과된 것을 확인했습니다.
Annotation & Aop 적용
분산 락은 잘 적용되었지만, 코드를 살펴보니 비즈니스 로직에 락(Distributed Lock) 획득과 반납을 처리하는 코드가 포함되어 있었습니다. 이러한 코드는 트랜잭션의 시작과 종료처럼 횡단 관심사에 해당한다고 판단했습니다. 이를 분리하기 위해 어노테이션(Annotation)과 AOP(Aspect-Oriented Programming)를 활용해 락 관련 로직을 분리하고 정리했습니다.
DistributedLock.java
/**
* Redisson Distributed Lock annotation
*/
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface DistributedLock {
/**
* 락의 이름
*/
String key();
/**
* 락의 시간 단위
*/
TimeUnit timeUnit() default TimeUnit.SECONDS;
/**
* 락을 기다리는 시간 (default - 10s) 락 획득을 위해 waitTime 만큼 대기한다
*/
long waitTime() default 10L;
/**
* 락 임대 시간 (default - 3s) 락을 획득한 이후 leaseTime 이 지나면 락을 해제한다
*/
long leaseTime() default 3L;
}DistributedLock 어노테이션의 파라미터는 key는 필수, 나머지 값들은 커스텀하게 설정할 수 있도록 작성했습니다.
DistributedLockAop.java
/**
* @DistributedLock 선언 시 수행되는 Aop class
*/
@Aspect
@Component
@RequiredArgsConstructor
@Slf4j
public class DistributedLockAop {
private static final String REDISSON_LOCK_PREFIX = "LOCK:";
private final RedissonClient redissonClient;
private final AopForTransaction aopForTransaction;
@Around("@annotation(com.ureca.filmeet.global.annotation.DistributedLock)")
public Object lock(final ProceedingJoinPoint joinPoint) throws Throwable {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
DistributedLock distributedLock = method.getAnnotation(DistributedLock.class);
String key = REDISSON_LOCK_PREFIX + CustomSpringELParser.getDynamicValue(signature.getParameterNames(),
joinPoint.getArgs(), distributedLock.key());
RLock rLock = redissonClient.getLock(key); // (1)
try {
boolean available = rLock.tryLock(distributedLock.waitTime(), distributedLock.leaseTime(),
distributedLock.timeUnit()); // (2)
if (!available) {
return false;
}
return aopForTransaction.proceed(joinPoint); // (3)
} catch (InterruptedException e) {
throw new InterruptedException();
} finally {
try {
if (rLock.isLocked() && rLock.isHeldByCurrentThread()) {
rLock.unlock(); // (4)
}
} catch (IllegalMonitorStateException e) {
log.info("Redisson Lock Already UnLock serviceName {} key {}", method.getName(), key);
}
}
}
}다음은 @DistributedLock 어노테이션 선언 시 수행되는 aop 클래스입니다.
@DistributedLock 어노테이션의 파라미터 값을 가져와 분산락 획득 시도 그리고 어노테이션이 선언된 메서드를 실행합니다.
- 락의 이름으로 RLock 인스턴스를 가져온다.
- 정의된 waitTime까지 획득을 시도한다, 정의된 leaseTime이 지나면 잠금을 해제한다.
- DistributedLock 어노테이션이 선언된 메서드를 별도의 트랜잭션으로 실행한다.
- 종료 시 무조건 락을 해제한다.
여기서 주의해서 볼 부분은 CustomSpringELParser와 AopForTransaction 클래스입니다.
이 클래스들은 분산락 컴포넌트에서 어떤 역할을 맡고 있을까요?
CustomSpringELParser.java
/**
* Spring Expression Language Parser
*/
public class CustomSpringELParser {
private CustomSpringELParser() {
}
public static Object getDynamicValue(String[] parameterNames, Object[] args, String key) {
ExpressionParser parser = new SpelExpressionParser();
StandardEvaluationContext context = new StandardEvaluationContext();
for (int i = 0; i < parameterNames.length; i++) {
context.setVariable(parameterNames[i], args[i]);
}
return parser.parseExpression(key).getValue(context, Object.class);
}
}CustomSpringELParser는 전달받은 Lock의 이름을 Spring Expression Language로 파싱 하여 읽어옵니다.
// (1)
@DistributedLock(key = "#lockName")
public void shipment(String lockName) {
...
}
// (2)
@DistributedLock(key = "#model.getName().concat('-').concat(#model.getShipmentOrderNumber())")
public void shipment(ShipmentModel model) {
...
}
ShipmentModel.java
public class ShipmentModel {
private String name;
private String shipmentNumber;
public String getName() {
return name;
}
public String getShipmentNumber() {
return shipmentNumber;
}
...
}Spring Expression Language를 사용하면 다음과 같이 Lock의 이름을 보다 자유롭게 전달할 수 있습니다.
AopForTransaction.java
/**
* AOP에서 트랜잭션 분리를 위한 클래스
*/
@Component
public class AopForTransaction {
@Transactional(propagation = Propagation.REQUIRES_NEW)
public Object proceed(final ProceedingJoinPoint joinPoint) throws Throwable {
return joinPoint.proceed();
}
}@DistributedLock 이 선언된 메서드는 Propagation.REQUIRES_NEW 옵션을 지정해 부모 트랜잭션의 유무에 관계없이 별도의 트랜잭션으로 동작하게끔 설정했습니다. 그리고 반드시 트랜잭션 커밋 이후 락이 해제되게끔 처리했습니다.
AOP를 적용한 서비스 로직
@DistributedLock(key = "'movieLikes:' + #movieId")
@Override
public void movieLikes(Long movieId, Long userId) {
boolean isAlreadyLiked = movieLikesRepository.existsByMovieIdAndUserId(movieId, userId);
if (isAlreadyLiked) {
throw new MovieLikeAlreadyExistsException();
}
Movie movie = movieRepository.findMovieWithGenreByMovieId(movieId)
.orElseThrow(MovieNotFoundException::new);
User user = userRepository.findById(userId)
.orElseThrow(MovieUserNotFoundException::new);
MovieLikes movieLikes = MovieLikes.builder()
.movie(movie)
.user(user)
.build();
movieLikesRepository.save(movieLikes);
updateGenreScoresForUser(userId, movie, GenreScoreAction.LIKE);
movie.addLikeCounts();
}테스트 코드
@DisplayName("좋아요_개수_분산락_적용_락_흐름조정_AOP_사용_동시성_1000명_테스트")
@Test
void likeCountWithDistributedLockAdjustedFlowUsingAOPConcurrency1000Test() throws InterruptedException {
// given
Movie movie = createMovie("제목", "줄거리", LocalDate.now(), 150, "https://poster.jpg", FilmRatings.ADULT);
Genre genre = createGenre(GenreType.ACTION);
MovieGenre movieGenre = createMovieGenre(movie, genre);
movieRepository.save(movie);
genreRepository.save(genre);
movieGenreRepository.save(movieGenre);
List<User> users = new ArrayList<>();
for (int i = 1; i <= 1000; i++) {
User user = createUser("user" + i, "password", Role.ROLE_ADULT_USER, Provider.NAVER, "닉네임" + i,
"https://example.com/profile" + i + ".jpg");
users.add(user);
}
userRepository.saveAll(users);
// when
int numberOfThreads = 1000;
ExecutorService executorService = Executors.newFixedThreadPool(numberOfThreads);
CountDownLatch latch = new CountDownLatch(numberOfThreads);
for (int i = 0; i < numberOfThreads; i++) {
long userId = users.get(i).getId();
executorService.submit(() -> {
try {
movieLikeCommandServiceV4.movieLikes(movie.getId(), userId);
} finally {
latch.countDown();
}
});
}
latch.await();
executorService.shutdown();
// then
Optional<Movie> findMovie = movieRepository.findById(movie.getId());
assertThat(findMovie).isPresent();
assertThat(findMovie.get().getLikeCounts()).isEqualTo(1000);
}
테스트 결과는 잘 통과된 것을 확인했습니다.
마무리하며
지금까지 영화 좋아요 등의 동시성 문제를 해결하기 위해 분산 락(Distributed Lock)을 적용한 과정을 소개해 드렸습니다. 분산 락을 도입함으로써 보다 안정적이고 수준 높은 락 처리가 가능해졌습니다. 또한, AOP(Aspect-Oriented Programming)를 활용해 락 관련 로직을 핵심 비즈니스 로직과 분리함으로써 생산성과 가독성이 모두 향상되었습니다.
긴 글 읽어주셔서 감사합니다.
참고
https://helloworld.kurly.com/blog/distributed-redisson-lock/
https://mangkyu.tistory.com/311
https://velog.io/@a01021039107/Redisson%EC%9D%98-RLock%EC%9D%84-%EC%95%8C%EC%95%84%EB%B3%B4%EC%9E%90
https://hyperconnect.github.io/2019/11/15/redis-distributed-lock-1.html
https://sungsan.oopy.io/5f46d024-dfea-4d10-992b-40cef9275999
'프로젝트 > Filmeet' 카테고리의 다른 글
| API 성능 테스트부터 최적화까지 – 15초에서 0.1초로, 병목 해결 여정 (1) | 2024.12.22 |
|---|---|
| 콘텐츠 기반 추천과 유사 사용자 기반 추천을 결합한 하이브리드 추천 시스템 만들기 (3) | 2024.12.19 |
| @Query with "not in" not work with empty List parameter (0) | 2024.12.02 |
| MultipleBagFetchException - 두 개 이상의 OneToMany 관계에서 N+1 문제 최적화하기 (0) | 2024.11.22 |
| 동적 조건 처리를 위한 Querydsl 사용하기 (0) | 2024.11.21 |